Method
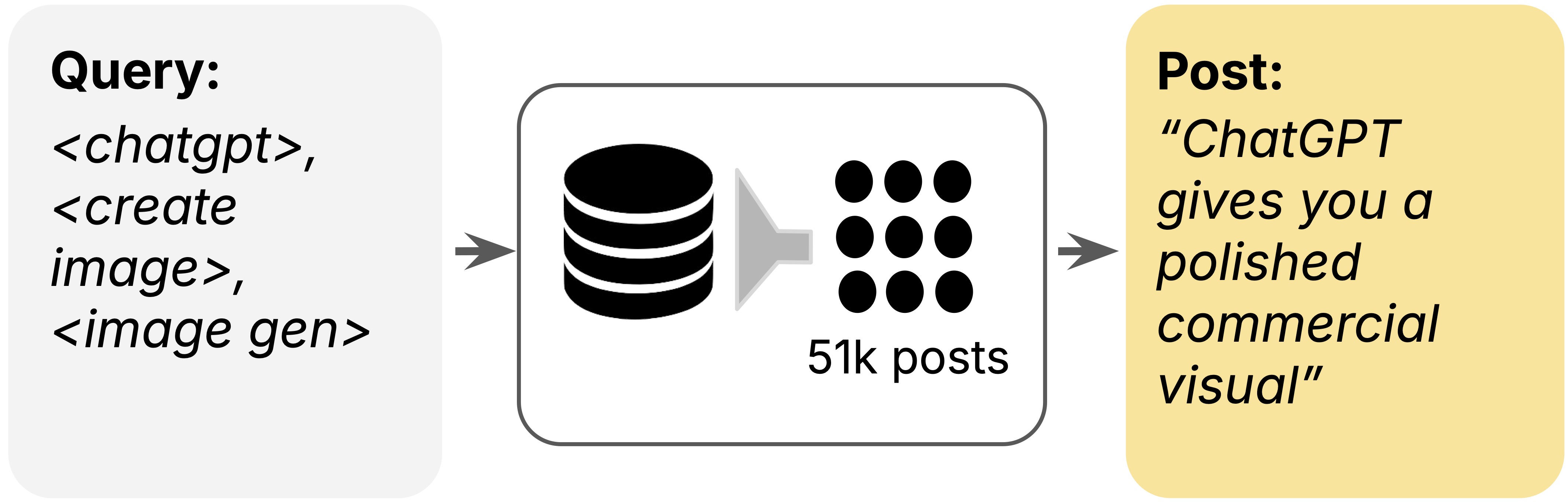
To collect these examples, we develop a framework called ECHO: Extracting Community Hatched Observations. We design this framework to address a number of challenges inherent to social media. Click through the tabs below to learn more about each step.
Collect large volume of relevant posts
Large-scale collection is bottlenecked by a volume-relevance tradeoff. When querying with broader keywords, the average post relevance goes down, and with narrower ones, the available post pool is quickly exhausted. We therefore implement a two-stage pipeline, where we first query for a large volume of posts then use an LLM to filter irrelevant ones.
Reconstruct context with post trees
Posts can be context dependent. For example, a user may write "prompt below" in the first post then include the actual prompt text in a reply. To extract self-contained prompts, our framework attempts to collect as much of the reply tree as possible, then use this full context when processing posts into samples.
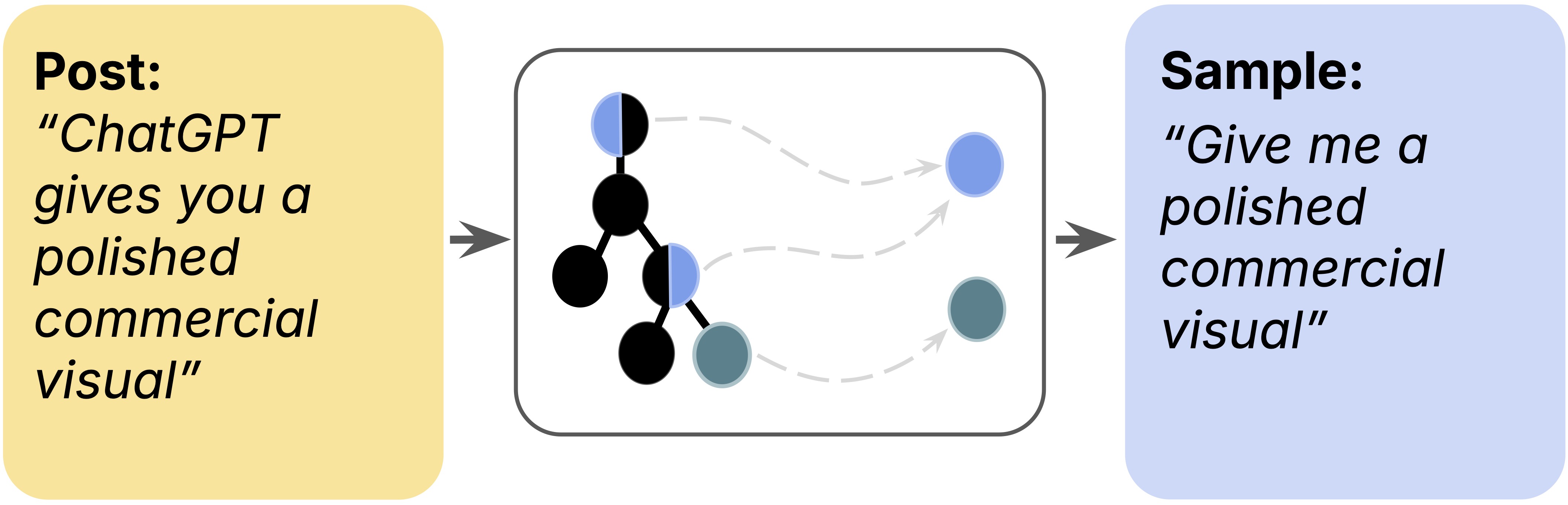
Process multimodal data in non-standard formats
Useful data exists in non-standard formats. The output image could be the first or the last in a series of images, the prompt may be written in an incomplete fill-in-the-blank format, or data may be embedded in a screenshot. We process these cases with a VLM, which is responsible for classifying input vs. output images, filling in blanks, or parsing screenshots.



Finalize samples
Data quality varies widely. A user may provide more general commentary or exactly document their input prompt. We separate prompts into two groups: moderate-quality ones suited for analysis, and high-quality ones appropriate for benchmarking.

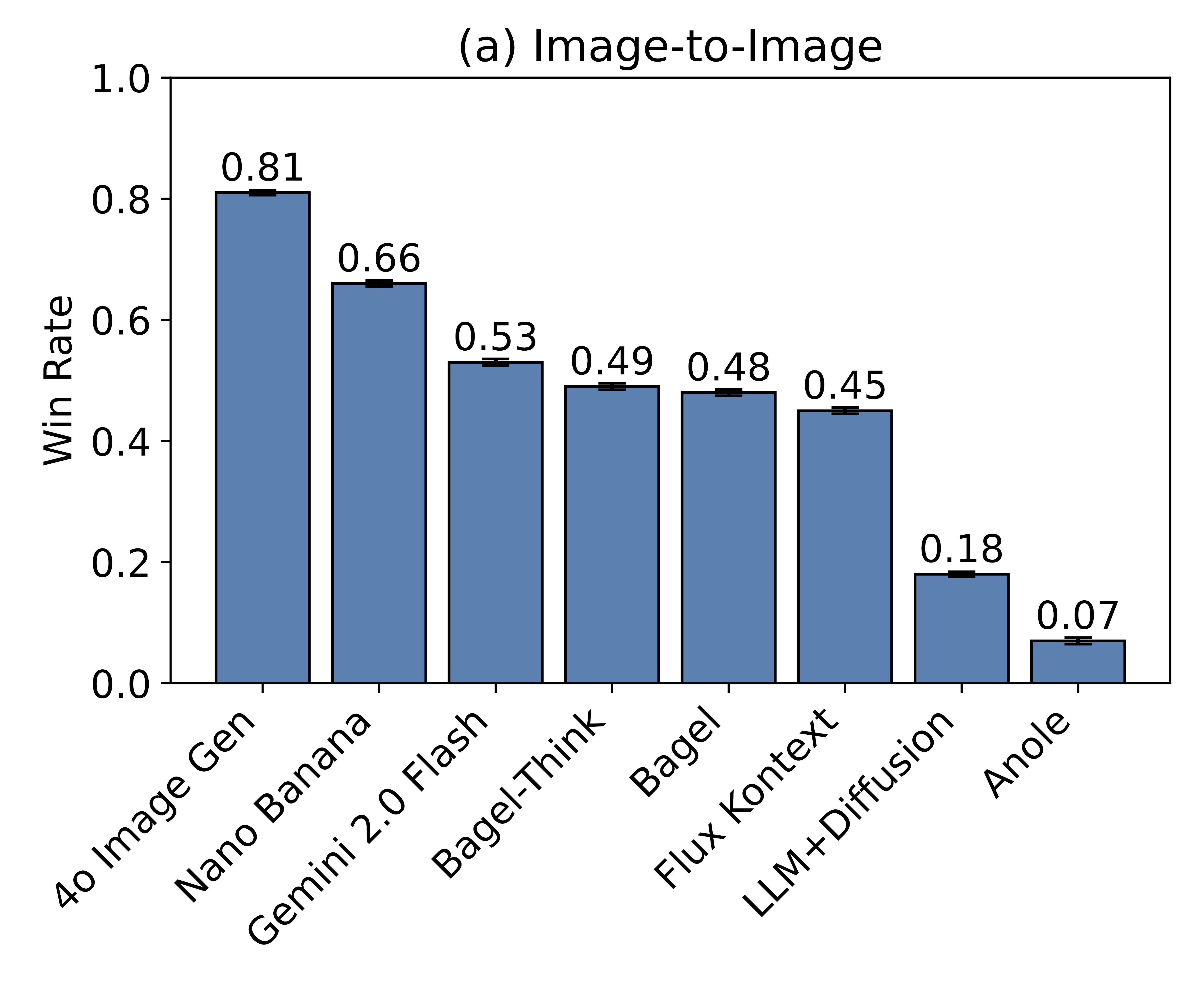
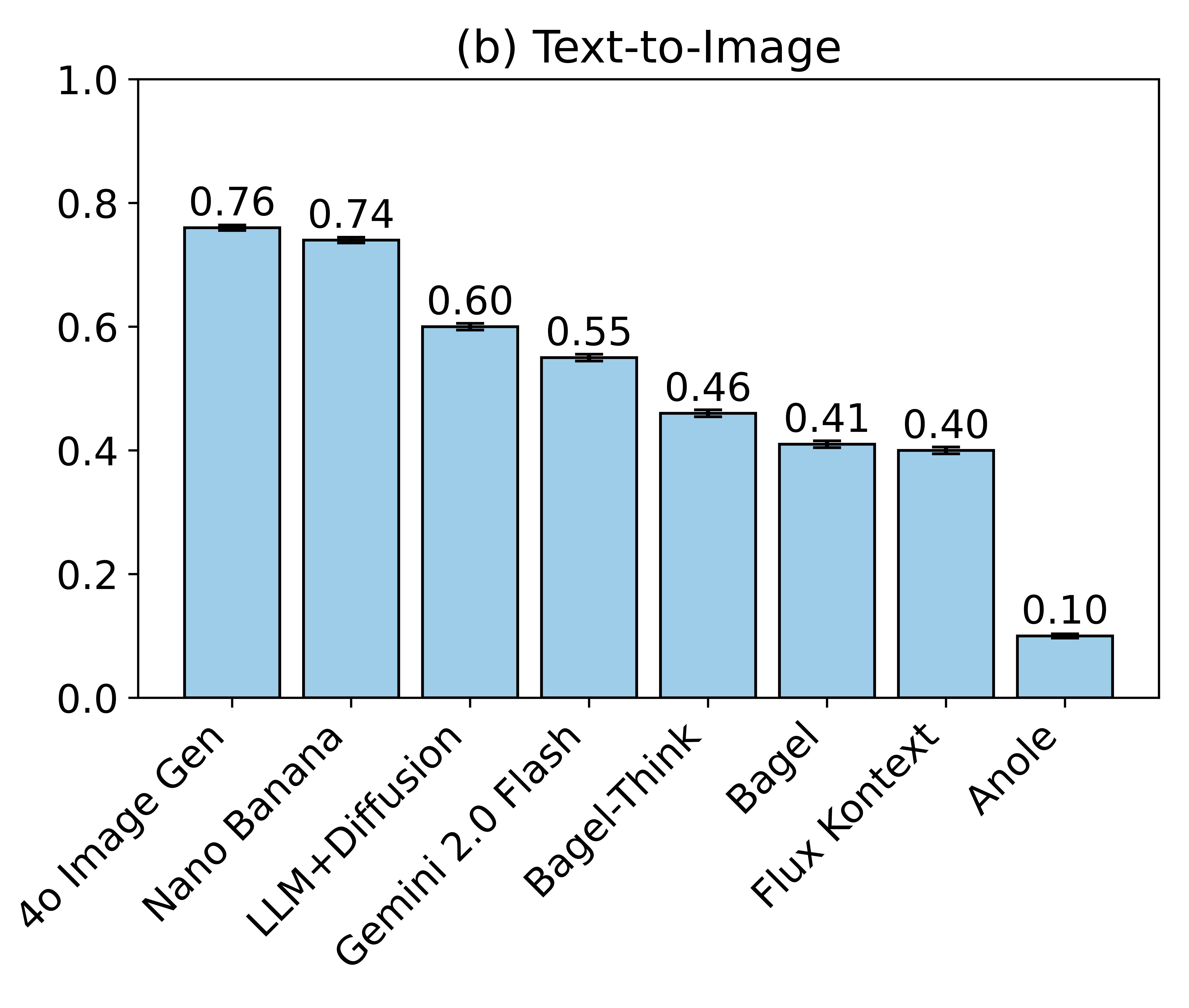
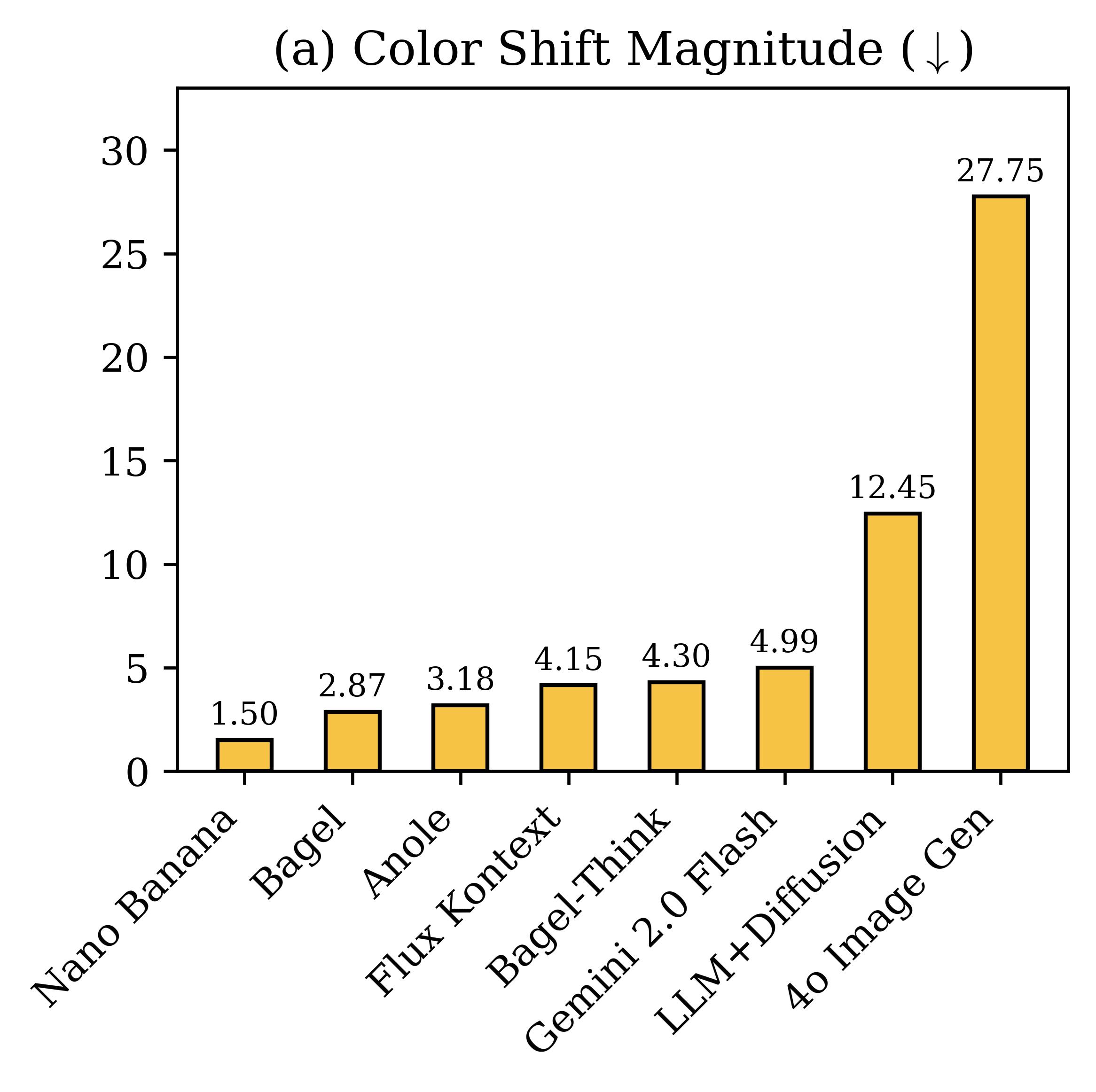
 Select from the dropdown above then hover over the plot
Select from the dropdown above then hover over the plot